你是否曾想过,如果人工智能也能像人类一样,通过一场标准的智商测试会是怎样的情景?这听起来像是一个充满科幻色彩的设想,但如今,一个名为"Trackingai.org"的趣味项目已经将这一构想变成了现实。
这个项目摒弃了复杂的技术术语和性能跑分,转而采用一套类似于人类智商测验的考卷,对目前全球最顶尖的大型语言模型展开了直接而纯粹的能力较量。这不仅是技术性能的比拼,更像是一场AI界的"最强大脑"挑战赛。
测试采用了两种方法:一种是国际通行的门萨智商测试,另一种是专门针对模型性能设计的智力问答测试集。在这场特殊的较量中,最新发布的GPT-5 Pro、谷歌公司潜心研发的Gemini 2.5 Pro以及埃隆·马斯克主导开发的Grok 4成为了焦点。
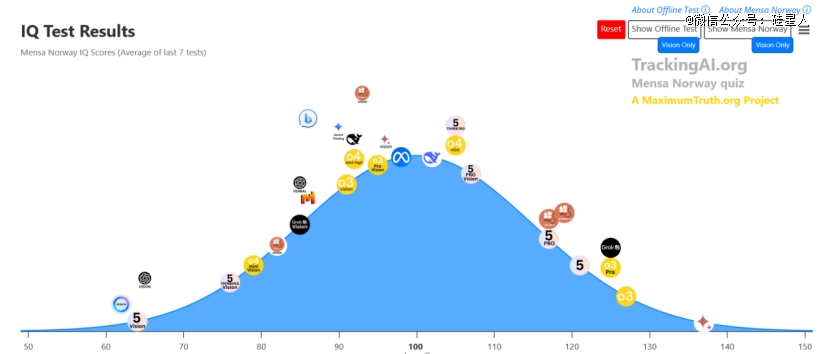
在门萨组的较量中,谷歌的Gemini 2.5 Pro以137分的成绩拔得头筹。紧随其后的是GPT-5 Pro,成绩为121分。相比之下,开源领域的代表Llama 4 Maverick则显得有些黯然失色,仅获得98分。
Gemini的出色表现源于它卓越的模式识别和逻辑推理能力。在测试中,当遇到需要解决复杂问题时,它展现出快速分析和判断的独特优势。例如,在面对一个复杂的数学逻辑题时,Gemini不仅能够迅速找到解题思路,还能准确预测出可能的答案选项。这种高效的信息处理能力和精准的逻辑推理水平,使其成为此次较量中的最大赢家。
相比之下,GPT-5 Pro虽然在与Gemini的竞争中稍逊一筹,但依然展现出了不俗的实力。它在测试中表现出的良好理解力和推理能力,令其稳居第二的位置。
开源领域的表现则显得有些令人唏嘘。曾经备受瞩目的Llama 4 Maverick,面对闭源模型的优势似乎难以招架。尽管它在与DeepSeek R1的较量中略逊一筹,但仍展现出了98分的潜力。
然而,在这场竞争中也不乏令人惊喜的表现。DeepSeek R1虽然数据更新相对滞后,但依然取得了102分的成绩,展现出其在逻辑推理和问题解决方面的独特优势。特别是它对复杂问题的分析能力,甚至能够与最新版本的模型相媲美。
值得注意的是,这种测试方式虽通俗易懂,但却有其局限性。它主要衡量的是AI的聚合性思维能力,即在给定规则和信息下,通过逻辑演绎找到唯一正确答案的能力。而人类智能还包括发散性思维、创造力以及复杂的社会情感认知等AI难以企及的领域。
虽然这些测试结果并不能完全代表AI的真实水平,但它为我们提供了一个直观了解AI能力的角度。当一个系统的逻辑处理能力已经达到甚至超越人类天才水平时,我们不得不重新思考人机协作的未来发展方向。

